The problem of missing persons is a deeply unsettling and complex issue. In the United States, countless women have been reported missing, with cases dating back decades. But what if data science could help us find patterns in these tragedies? Could machine learning algorithms detect hidden trends and provide new insights?
This project sets out to answer these questions. By leveraging data from Kaggle and applying advanced clustering techniques, the project aims to bring a new perspective to the issue of missing women across the United States from 1944 to 2020.
The Power of Data: What the Dataset Tells Us
The dataset includes detailed records of missing females, providing key information such as names, dates, last known locations, physical characteristics, and more. With over 6,800 entries, this dataset represents a vast amount of information, but it also poses a significant challenge: how do we make sense of all this unstructured data?
Unsupervised machine learning models are particularly suited to this kind of challenge. Without predefined categories or labels, these models can group similar cases and identify underlying structures within the data. For this project, two key techniques were applied: K-means clustering and DBSCAN spatial clustering.
Step 1: Exploring the Data
Before diving into machine learning, the first task was to explore the data. This Exploratory Data Analysis (EDA) phase is crucial for cleaning the dataset and gaining a preliminary understanding of its contents.
One of the major hurdles was dealing with missing data. In a dataset about missing persons, it’s not surprising that key information might be missing—such as the race, height, or weight of individuals. However, to ensure a smooth analysis, all rows containing empty values were removed, which reduced the dataset but made it more manageable. With the dataset cleaned, patterns began to emerge. Grouping the data by race, for example, revealed differences in age, height, and weight across different demographics. The project also computed correlations between these variables, adding further insights into the relationships between them.
Step 2: Finding Hidden Groups with K-means Clustering
Once the data was prepared, the next step was applying K-means clustering—a technique used to partition data into distinct groups based on feature similarity. This method is particularly useful when the goal is to uncover hidden patterns, especially when dealing with unlabeled data.
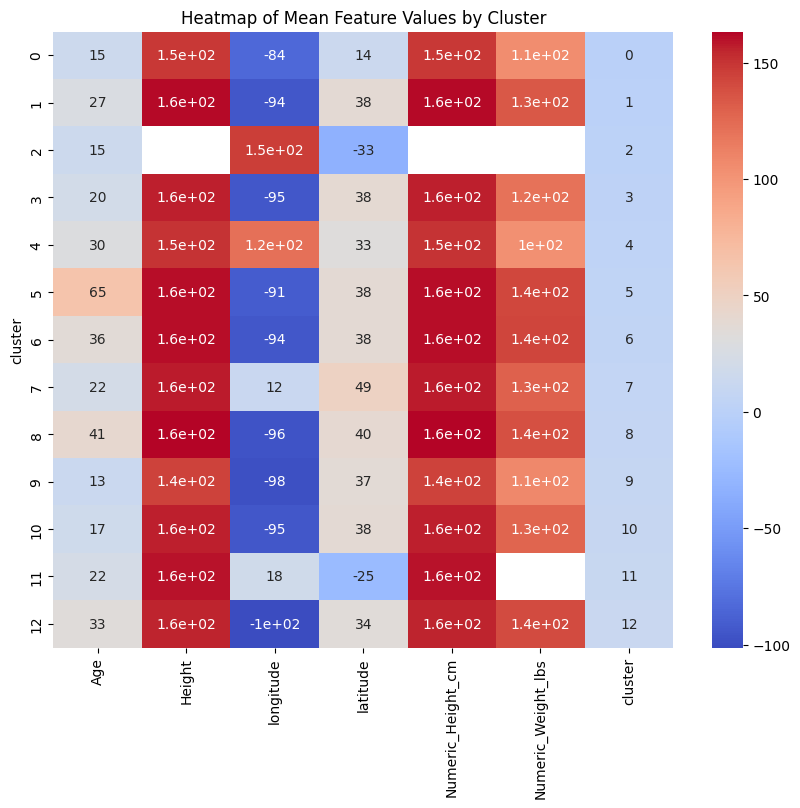
To find the optimal number of clusters, the silhouette score was used. After testing various cluster numbers, the model determined that dividing the dataset into 13 clusters provided the most meaningful results. These clusters offered a glimpse into different “types” of missing female cases, based on their physical characteristics such as age, height, and weight.
Visualizing these clusters provided even more clarity. Scatter plots and radar charts made it easy to see the defining traits of each group, offering a fresh way to think about missing person cases. Are there physical characteristics that are more common in certain age groups or regions? What about racial differences? These clusters help raise such questions, giving data-driven insights into these long-standing concerns.
Step 3: Mapping Geographic Trends with DBSCAN
While K-means clustering revealed hidden patterns in the dataset based on physical characteristics, it couldn’t help us understand the geographic dimension of these cases. That’s where DBSCAN (Density-Based Spatial Clustering of Applications with Noise) came in.
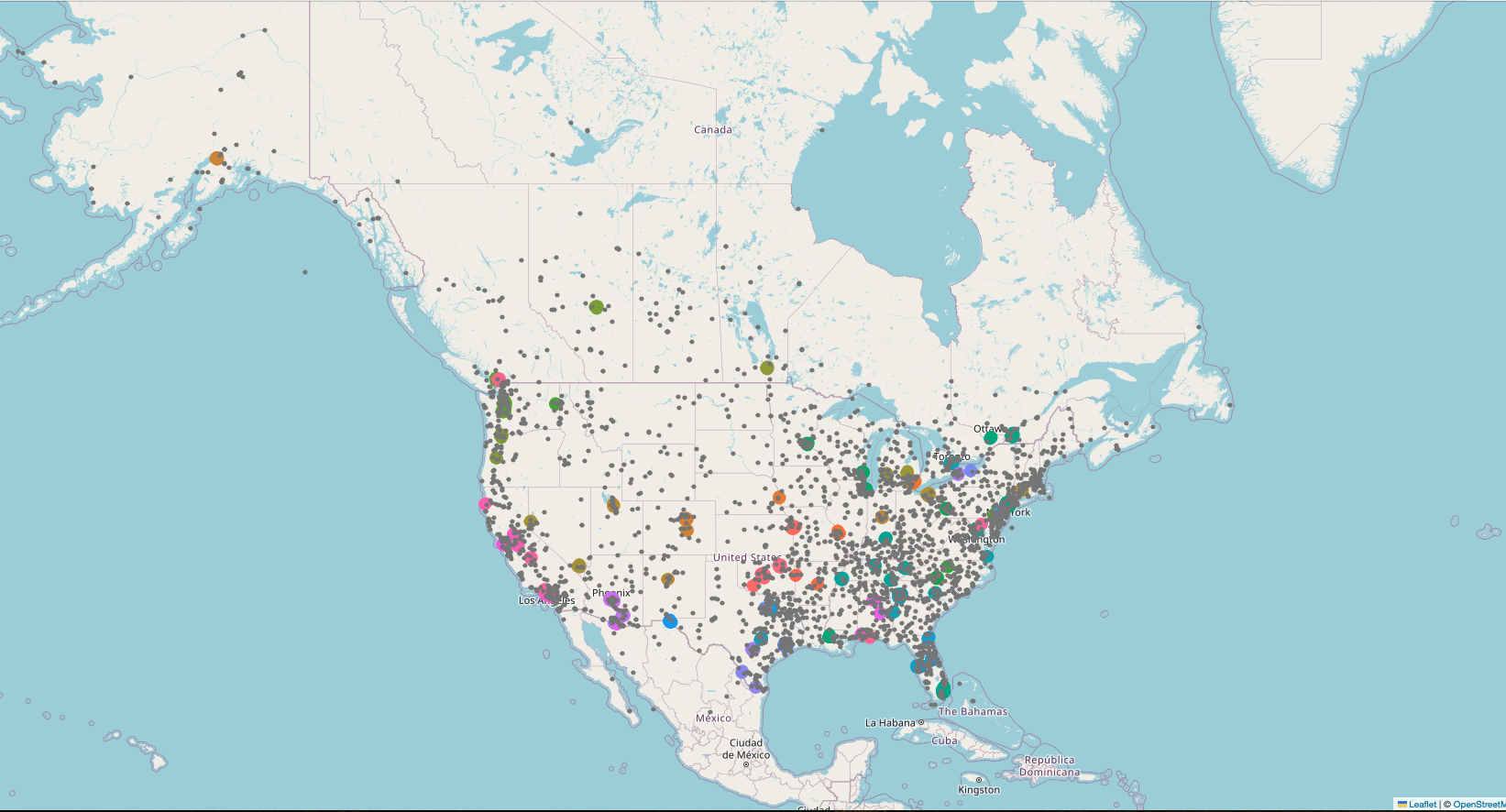
DBSCAN is a spatial clustering algorithm designed to find clusters of varying shapes and sizes—perfect for analyzing geographic data. By focusing on the longitude and latitude of the last known locations of missing females, this technique helped pinpoint regional “hotspots” where multiple disappearances occurred.
Unlike K-means, which assumes that clusters are spherical, DBSCAN allows for irregular cluster shapes—an essential feature when analyzing geographic data. The project discovered clusters across the USA and Canada, indicating areas where cases were concentrated. This kind of spatial analysis can be incredibly valuable for law enforcement and organizations trying to understand where resources should be allocated.
Key Findings and Insights
The results of this project were both revealing and concerning: Demographic Disparities: The analysis showed that missing females are not distributed evenly across racial groups. Some racial groups have younger average ages, while others display distinct physical characteristics.
Geographic Hotspots: Certain regions in the United States have a disproportionately high number of missing females. These areas could be subject to further investigation to understand whether regional factors might be contributing to the problem.
Common Case Profiles: Through clustering, the project was able to group cases with similar characteristics, potentially offering insights into profiling and identifying common factors in disappearances.
Challenges and Limitations
While the analysis yielded valuable insights, it also faced several limitations. The biggest challenge was the amount of missing data, which led to some cases being excluded from the analysis. This may have introduced bias and limited the generalizability of the findings.
Additionally, the dataset itself lacks the kind of detailed case outcomes that would allow for more specific predictions or classifications. Despite these limitations, the project demonstrates the potential of data science to uncover hidden patterns in complex social issues.
Conclusion: A New Way to Think About Missing Persons
This project highlights the potential of unsupervised machine learning in analyzing real-world problems like missing person cases. By applying techniques such as K-means and DBSCAN, it’s possible to uncover meaningful patterns that might otherwise remain hidden in the data.
The findings are not just academic; they have the potential to inform law enforcement, policy makers, and researchers working on missing persons cases. While more work is needed to refine these techniques and address data limitations, this project represents a step toward better understanding and addressing the troubling issue of missing females in the United States.
A live demo of this project you can see here, while the Github repo is available at this link.